
Case Study: AI-Driven Innovation with Squid Game - Season 2
To be clear, anyone can easily generate Ai images/video from a rapidly growing landscape of online platforms like Runway, Midjourney, KLING, & Sora. The real focus here is to self-host open source AI technology to evaluate it's practicality, ease of deployment, and explore experimental workflows currently impossible via mainstream ai web platforms.
Objectives
This case study serves as an exploration of unique AI applications in content creation utilizing only final footage from the recent Squid Game Season 2. The exploration highlights several AI-driven innovations that can enhance production workflows throughout the lifecycle of a film or series production. The key objective is exploring how footage from the series can solely be leveraged to create training sets to power AI generated image, video, and 3D Gaussian Splatting.
Objectives Overview
- Train a Flux.dev based LoRA from an image set collected from the series.
- Generate Flux images via ComfyUI utilizing the LoRA and various ControlNets.
- Image to Video generation utilizing the LoRA via ComfyUI and LTXV.
- Image to 3D Model via Nerf Studio and 3D Gaussian Splatting.
Constraints
One of the biggest constraints of the study is exploring what can be achieved from the released footage alone. With this constraint, it is easy to see the potential of some of the demonstrations especially when the training set is expanded to all dallies content and additional photography from on set locations in the future.
Also, as previously stated, another major requirement of this study is for all AI technologies to be self-hosted and deployed here at my home lab. This limitation aims to help build a deeper understanding of the underlying infrastructure and its true deployment capabilities in the field.
Before working in Tech, I was a independent line & post producer specializing in operations, efficiencies, and equity financing for film & commercial projects. Through self hosted deployment, I can evaluate how productions can most effectively interact with these technologies and determine how these tools could be deployed in the field by non tech minded creatives.
Server Setup
The server is a intel x64 based system running Proxmox LE as a hypervisor for various virtual instances. Proxmox has a new flavor of containerized virtual machines called LXC that can share pooled resources including GPUs. In this setup, many of the services are sharing an Nvidia RTX 3090 via LXC shared vGPU. This allows many applications to be segregated and powered at the same time utilizing only one physical GPU. Furthermore, some of the LXCs are passing the GPUs into Dockers deployments that share resources as well.

Exploration
1. LoRA Generation
Image Training Set
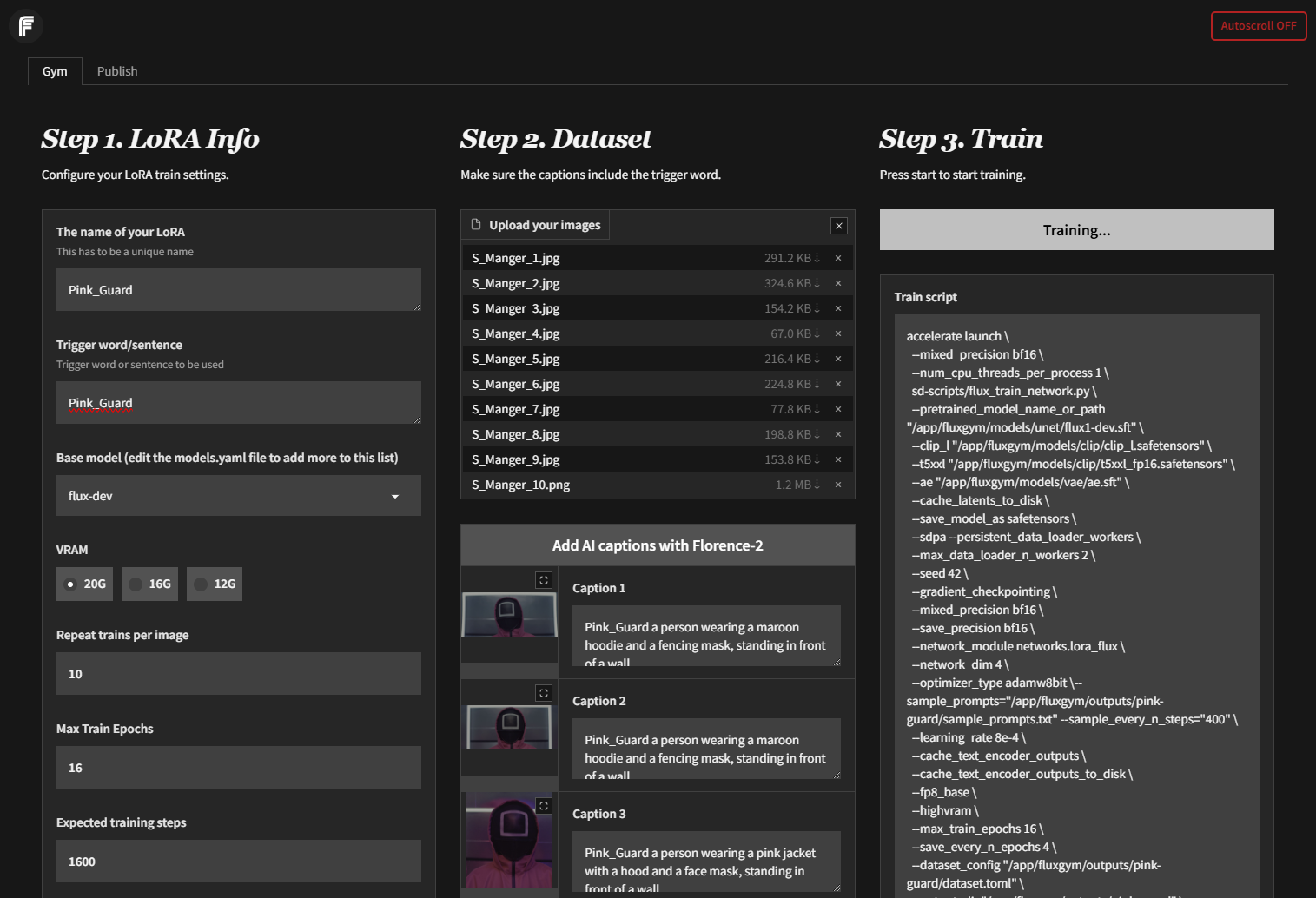
To create our custom LoRA (Low-Rank Adaptations), we must first collect a taining set of images of our subject or style. As we are only using images available in Season 2, a select of 10 screenshots of the Pink Guard Manager character were gathered. Here are a few of the images below:

LoRA Training - Flux Gym
Next we must find a good service that can train LoRAs for our image generation model of choice. In this case we have select Flux.dev, a 12 billion parameter rectified flow transformer that is the latest and greatest in the open source community.
Selecting a capable training tool that is also easy to use was quite challenging. Many on YouTube & Reddit pointed toward CLI based tools like AI-Toolkit and Kohya Scripts, both of which are not deployment friendly. However, Flux Gym is a tool designed specifically for LoRA generation for Flux and is a graphical frontend built on top of Kohya scripts with and existing Docker Container deployment. Added it quickly to the stack via dockage and we were off to the races. I added all 10 images and used the Florence-2 integration to automatically add descriptions of the images using the local based model.
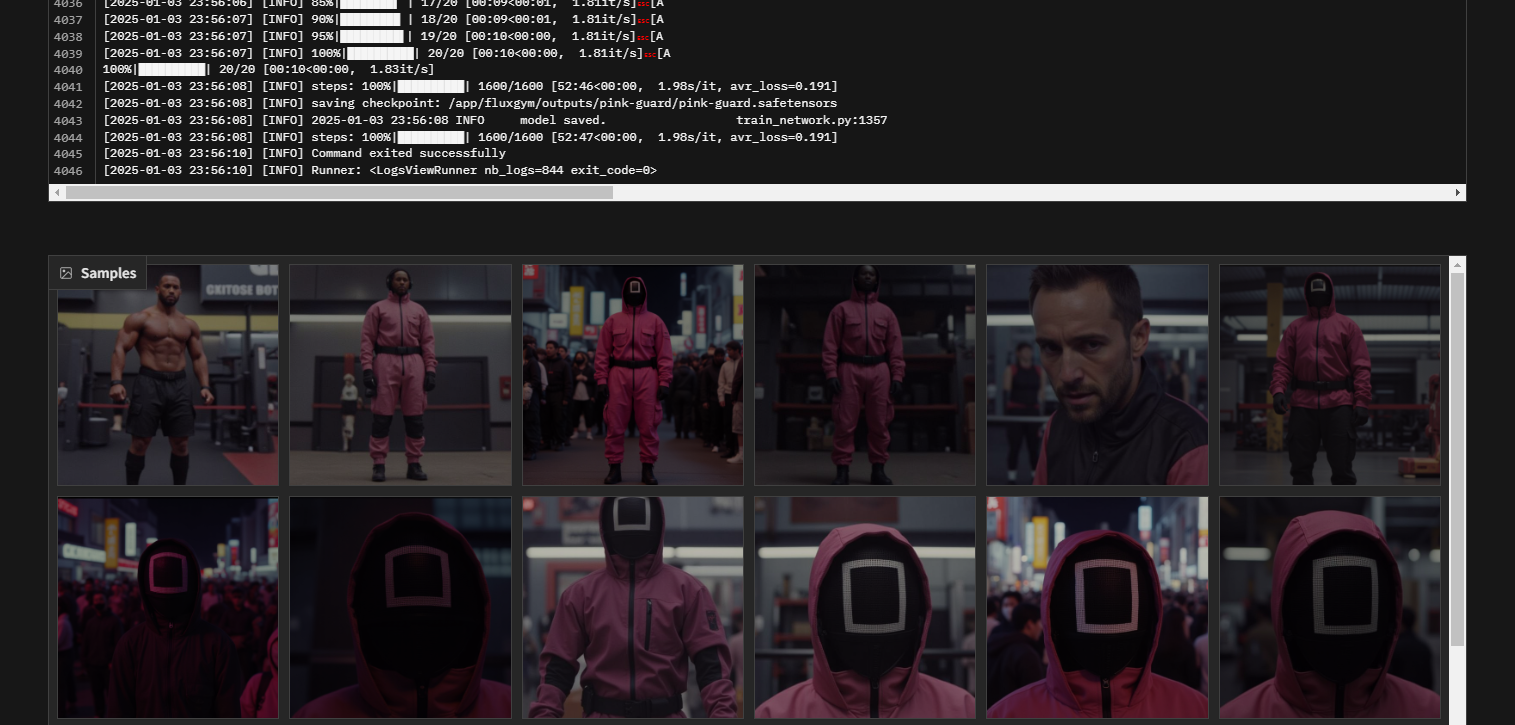
Along the way you can actually schedule image generation to watch the LoRA evolve. As you can see below it was having a little trouble early on...
2. Image Generation
ComfyUI Workflow
To generate the images and later video, ComfyUI was selected as the main frontend as it is one most flexible and widely used toolsets in the open source community. Node based workflows are certainly the way of the future, and it was quick and easy to setup a few workflows inspired by the Flux demo set.
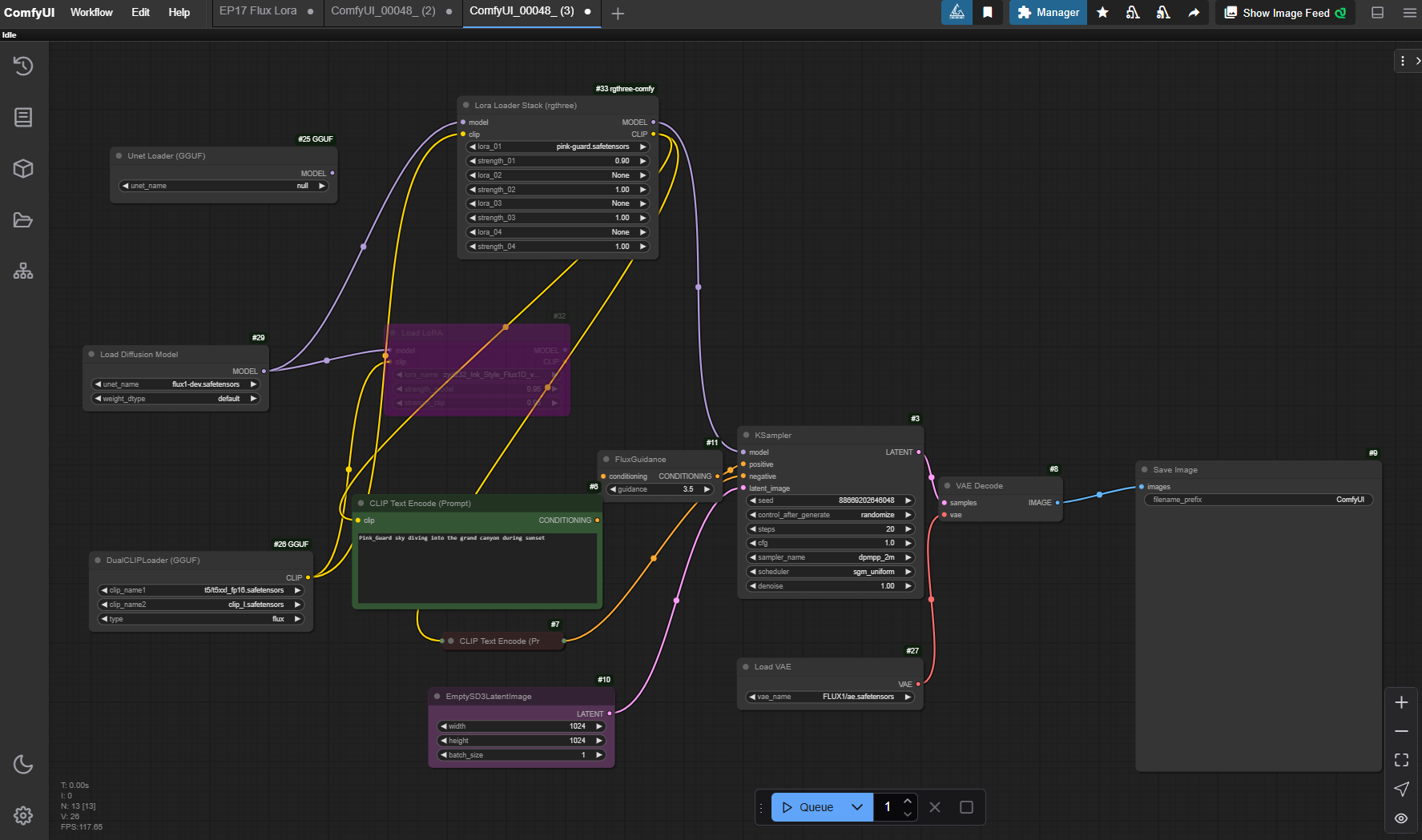
Now all we need is a prompt and away we go. Notice how the trigger work is "Pink_Guard". Also, feel free to drag and drop the generated images below into ComfyUI to access the specific workflow. I took a LoRA loaded approach to the workflow to stack LoRAs as we will see below.
Text Prompt:
Pink_Guard sky diving into the grand canyon during sunset

Stacked LoRA Images
This Flux AI generation can be expanded further to include multiple style LoRAs via the LoRA loader node. In this example below the Pink_Guard LoRA was combined with a publicly available CELEBRIT-AI DEATHMATCH Flux LoRA via CIVITAI.
Pink_Guard wearing a mask standing in a boxing ring in a celebrity deathmatach ready to fight looking at camera

This output showcasing the Pink Guard in a highly stylized version inspired by the aesthetics of the early 2000s MTV show Celebrity Deathmatch demonstrates the versatility of the AI models to adapt to different artistic styles. This can create a whole community of derivative content that can be created and shared to new immerging markets.
3. Video Generation
There are only a few open source video gen-ai models available today including Mochi, COGVideoX, LTX Video, and the new Hunyuan Video model. The number of video generate models will certainly explode over the next two quarters as the business model for many of these AI tech startups is to release early AI model builds to drive a community and following around an upcoming release. As LTX Video is currently stable and supports flux LoRA adaptation that will be the model of choice for this study.
ComfyUI LTX Video
Back to ComfyUI with a new LTX Video Workflow:
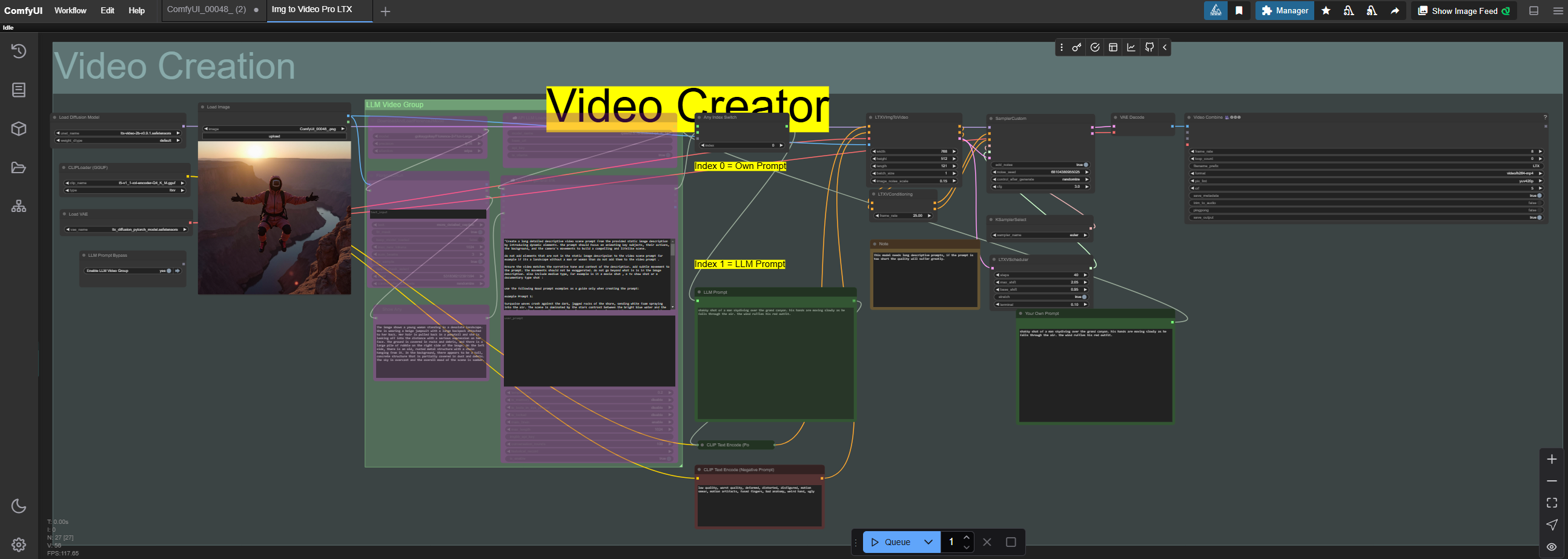
shaky shot of a man skydiving over the grand canyon. his hands are moving slowly as he falls through the air.
The wind ruffles his red outfit.

As you can see the above LTX Video output has many flaws, but demonstrates that self-hosted video AI generation is rapidly approaching. The key difference here between this ComfyUI demonstration is the utilization of a LoRA instead of an image to video functionality. With LoRA powered generation in the future, creatives can generate in combination with ControlNet tools to have much more flexibility and precise control beyond videos created solely from images. Text prompts generation is nice, but the future of generative AI is all about control, according to Hanno Basse, CTO Stability AI.
KLING Video Gen-AI
To demonstrate the mature state of commercial AI video generation platforms, lets take those same images and generate videos using KLING. A new emerging API driven video generation platform/model.
A man in a red jumpsuit is sky diving. The camera is shaky and tracks him as he falls down. He is moving
his arms and head up and down.


Notice the way the fabric reacts to the wind while the kneepads do not. Much better interpretation of skydiving then LTXV, but again leaves little creative control based flexibility beyond an image starting point.
4. Ai Automated Dubbing
(Updated 1/29/25) AI frameworks have also expanded into end-to-end lip sync functionality via KLING Lip Sync and open source tool LatentSync. In this example below we will start with an IMG to VIDEO via KLING.ai and then utilize Lip Sync to add our own text prompt.

IMG to Video Text Prompt:
A man smiling and looking away and back toward camera. The camera slowly pushes into his face.
Lip Sync Text:
Hello and welcome to Squid Games
Now there is definitely an uncanny nature to this solution, but again this was generate from a single image to video and a test using the raw clip could create a version that is many level above. Also, this models are at there first generation and demonstrate a future solution that will automated full dubbing solutions into any language.
Pairing this solution with Netflix's Timed Text Authoring Lineage (TTAL) as an API via JSON to a hosted LatentSyncnode, could be an amazing solution in the future. Further study of TTAL is needed with a specific eye toward clip cut points as this may need to be added or paired with a project file or XML that highlights clips sections for training. This could also be something gathered from an automated QC cut list from a local telestream instance etc.
5. IMG to 3D Modeling with AI
(Updated 1/29/25) With Microsoft's recent release of TRELLIS, AI is expanding into the 3D modeling world, where 2D images can be used to create 3D models of characters, objects, and even environments.
Hunyuan 3D-2 Model
This AI model was expanded further through clone via Hunyuan3D-2, which as been adopted for ComfyUI with modern GPU VRAM requirements of 24 GBs and below. Instead of self hosting this model and ComfyUI extension, I'll instead utilize Huggingface's Hunyuan3D-2 App. Let's try with our celebrity death match image from above.
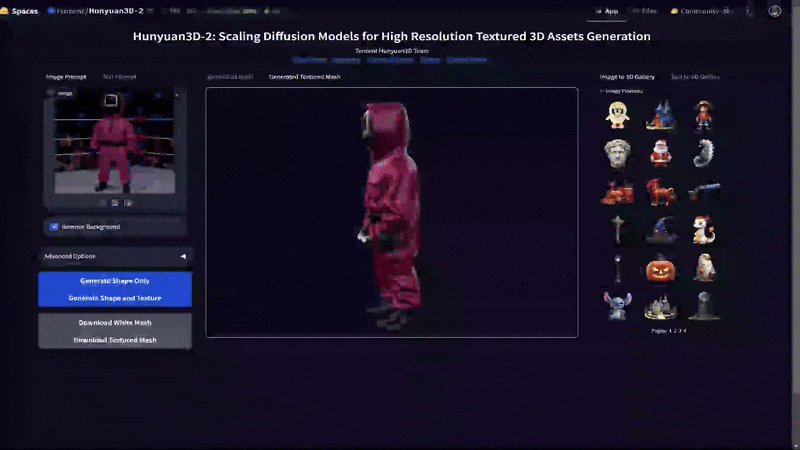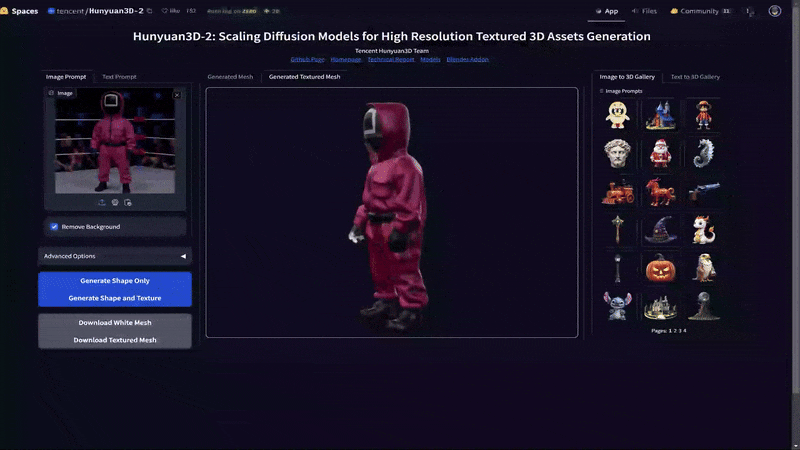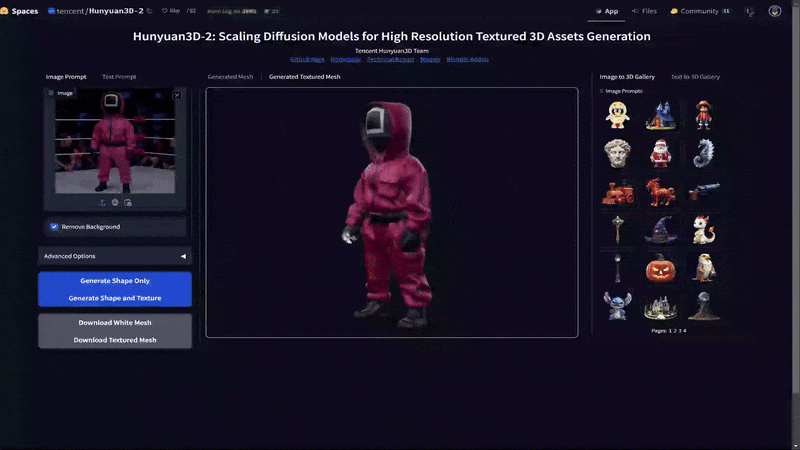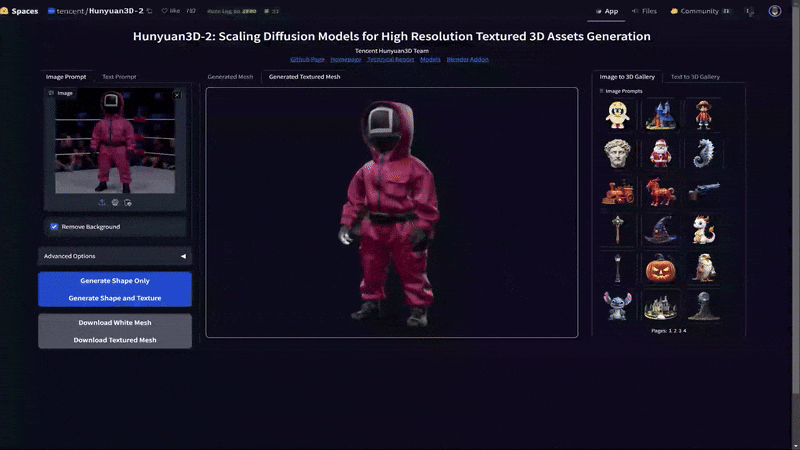
As you can see the AI model has done a decent job turning this into a textured Mesh. The area between the arms and body defiantly are not correct, but the basic concept is here. Now this model would need to be cleaned up considerably by a team, but it could serve as a great first step and is also only the first iterations of this type of AI application. As these models improve it will become more exact, driving easier asset and secondary content.
PlayCanvas Game Engine
As an example, I've imported the .glb textured mesh into PlayCanvas, which is a browser based game engine. This platform is limited in scope, but may serve to be a future alternative to Unreal Engine especially with the growing need for edge based compute and near time telemetry transport data for spatial applications. For this example, I've utilize the engine to build a simple game with the AI 3D model we created above. You can play it here: https://playcanv.as/p/8d2df0d8/
6. Gaussian Splat from shot
Now lets explore in a different area. Instead of initial generation from text prompt, images, or controlnet input, we could simply build a three dimensional representation of the scene and reposition shots where needed. In this approach we will utilize Nerf Studio in combination with COLAB to create a 3D Gaussian Splat from the following sniper push in shot from season 2.

Nerf Studio
Photogrammetry has been around a for awhile, but the latest innovations in Gaussian Splatting have enabled fast high quality rendering of complex 3D scenes. First we must install Nerf Studios and luckily there is docker container that also includes ffmpeg and COLAB pre installed!
First step is to get the video rendered into an several image sequences of various sizes:
ns-process-data video --data input/SG_2.mp4 --output-dir outputs/SG_2
Next we will build the Gaussian Splat, this process will first send images through the COLAB image position pipeline that determines each cameras orientation. These poisitions are imported automatically into Nerf Studio where the scene can start generation through iteration using AI.
ns-train gaussian-splatting --data outputs/SG_2

After 10-20 minutes you can already start to explore a 3D representation of the scene, which only gets better with time and iteration. Check out the 3D Scene here: https://nerf.nflix.dev
This 3D scene is not production ready, but demonstrates what is possible from one shot. Imagine if we trained using multiple takes and shots from the same scene. Or better yet, took a series of set photos that could be more easily stitched together to make a complete representation of the set in the future. The applications for this technology vary widely from visual effects composition to creating future assets for games and spatial content of the future.
Rendering Shots
As an example lets render out a new panning shot from this 3D scene:
ns-render camera-path --load-config outputs/SG_2/splatfacto/2025-01-03_211513/config.yml --camera-path-filename /workspace/outputs/SG_2/camera_paths/Pano.json --output-path renders/SG_2/Pano.mp4

Depth Map Output
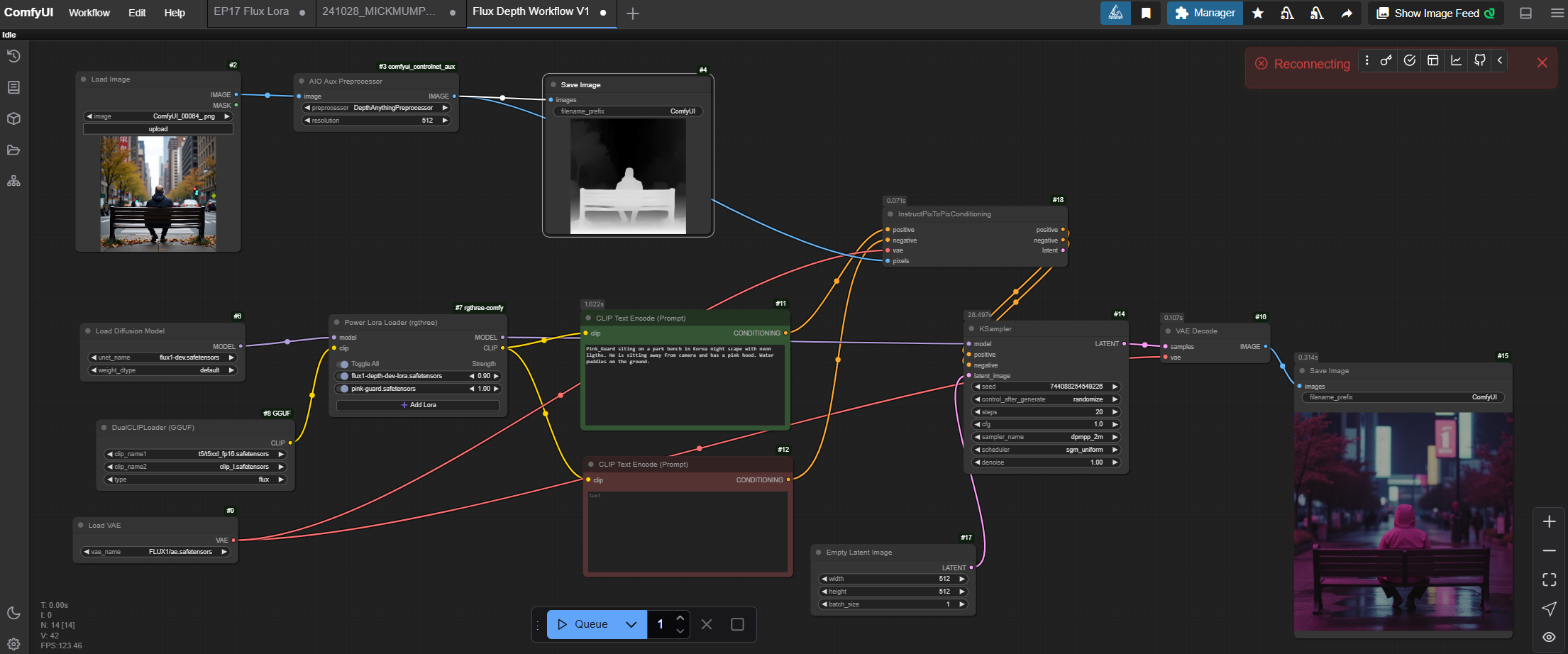
Beyond outputting a 3D scene we could also use this newly created gaussian splat to generate 2D depth maps that could be used again in ComfyUI via ControlNet nodes. This gives us the ability to take a physically shot scene and reposition creatively for a new image output.

Here is an example of a grey scale depth map output from Nerf Studio and could be easily used as a depth map for AI generation images via a InstructPixToPix Conditioning node in ComfyUI.
Pink_Guard siting on a park bench in Korea night scape with neon ligths. He is sitting away from camera
and has a pink hood. Water puddles on the ground.




Conclusion
By embracing AI across production workflows, Netflix is not only streamlining processes but also unlocking new realms of creative storytelling. Building assets libraries that train LoRAs & Gaussian splats could revolutionize the production and post production process by enabling creatives to rebuilt and fine tune existing footage from initial production. Also, the content creation opportunities are unimaginable in scale and can help foster a community that interacts with content building there own version and iterations to share and cross promote the series or film.